There is a task: given an image of a person, determine the distance between this person and the camera from which the given image was captured.
In this article, we will discuss terminology and theoretical foundations relevant to this task. In the next part, we will discuss the approach using synthetic data and present its initial results.
Coordinate system convention
This article is written with the following coordinate system in mind: The Z axis is aligned with the optical axis and increases in the view direction. X is perpendicular to Z and points to the right, and Y points downward.
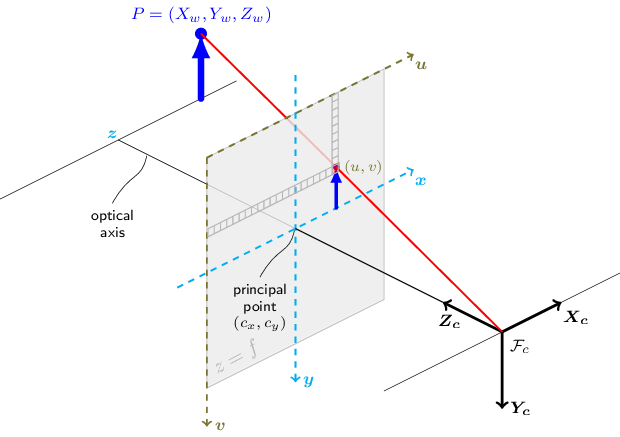
The figure above is taken from the OpenCV documentation.
Distance VS Depth
According to the research, the terms are used loosely and interchangeably. We looked into the MiDaS paper, Depth Anything V1 and V2 papers, and the KITTI website, and couldn’t find a certain definition of what they understand by depth. Papers with code website says: “Depth Estimation is the task of measuring the distance of each pixel relative to the camera”, which is quite ambiguous as they don’t mention the 3D scene itself (to which we measure the depth) and they don’t explain what exact distance is meant. This StackExchange post brings up the question of distance/depth ambiguity, and the top answer resolves it in favor of depth being just a Z-coordinate of a point of a 3D scene w.r.t. the camera’s coordinate system (with no proofs, though). However, it goes along with the definition of depth generally accepted in depth-from-stereo tasks.
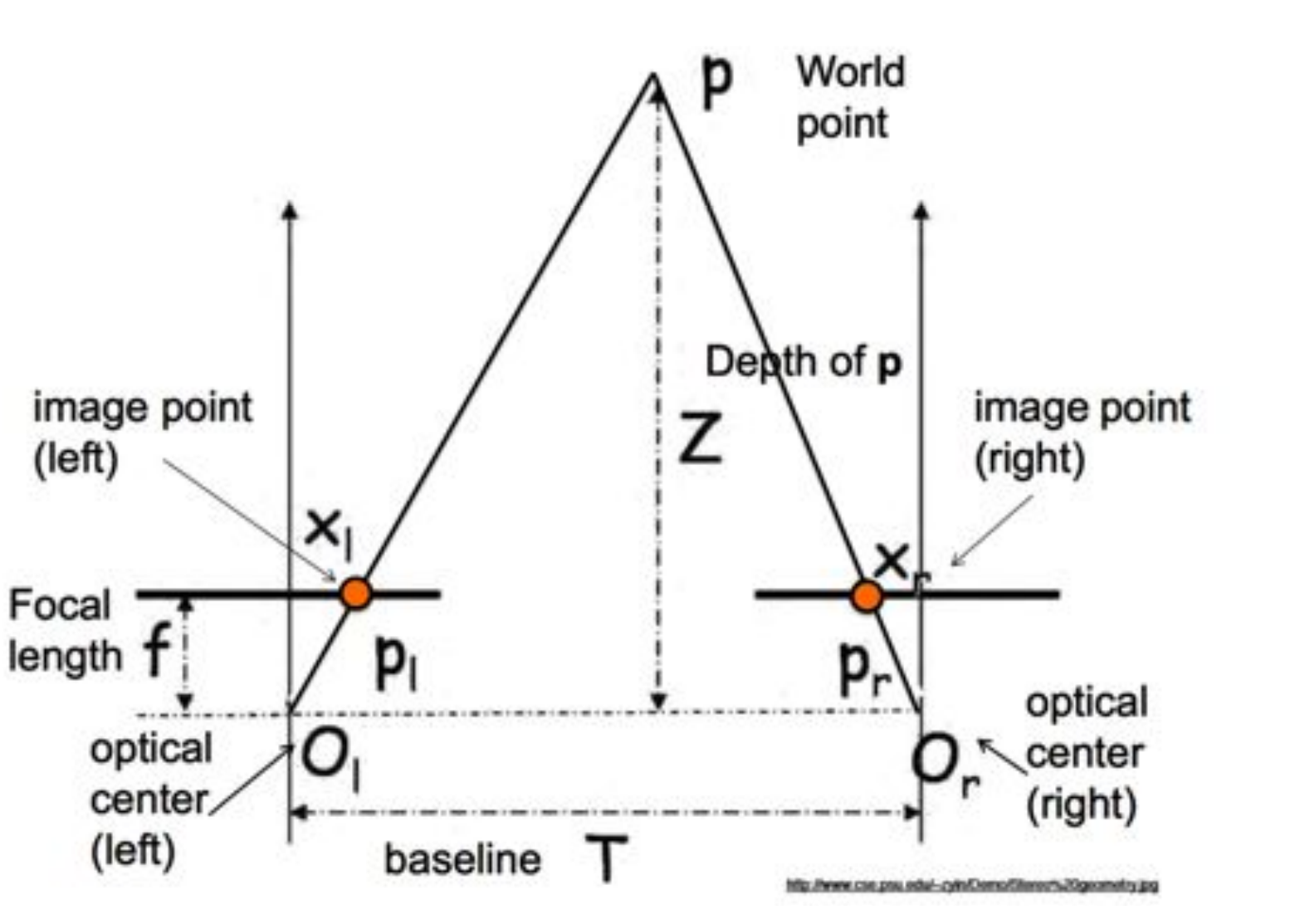
The image above illustrates that the Z coordinate is referred to as depth in the depth from stereo problem. Image source.
In this article, we will stick to the following understanding of distance and depth:
Distance to a point of a 3D scene is measured from the focal point (i.e., the center of projection, i.e., the origin of the camera’s coordinate system).
Depth of a point of a 3D scene is measured from the focal plane (the plane which is parallel to the image plane and contains the focal point, i.e., XY plane), hence, depth is equal to the Z coordinate of the object’s position in the camera’s coordinate system.
To gain a better intuition about the difference between depth and distance, imagine an image of a flat wall perpendicular to the camera’s view direction.
- Its depth map should be constant, because each point of the wall is at the same distance from the focal plane, and they have the same Z-coordinate.
- And on the contrary, the distance map can not be constant: points on the wall represented by pixels that are further from the center of the image will be further from the origin of the camera’s coordinate system compared to those in the middle of the image. Only the exact center of the distance map will have the same value as the depth map; every other pixel will have a higher value.
Also, there is a word “rangefinding” in the title of this article, so we believe it is important to mention that we consider “range” and “distance” to be complete synonyms in this context.
Now that we have defined from what point we measure, let’s define to which point we measure.
Our task does not require dense output. We are interested in the distance to a person as an object, not the distance to every pixel of the image. In this case, we have to define a point anchored to the human body to which we measure the distance.
And also, we need to define a (sub-)pixel location on the image, which we believe is the projection of that reference point on the human body. We need it to compute distance from depth, and/or to determine 3D coordinates of a person if needed (based on estimated depth/distance).
What this reference point on a human body should be is up to us to decide, and it depends on the application’s needs. However, it is rather arbitrary and not that important, since the difference in the measurements w.r.t. different reference points on the human body (e.g., center of mass, or middle point between the eyes, or the closest point on the surface of the body) will be smaller than the expected error of distance/depth estimation. In our synthetic dataset, such a “human anchor point” was located between the dummy’s feet.
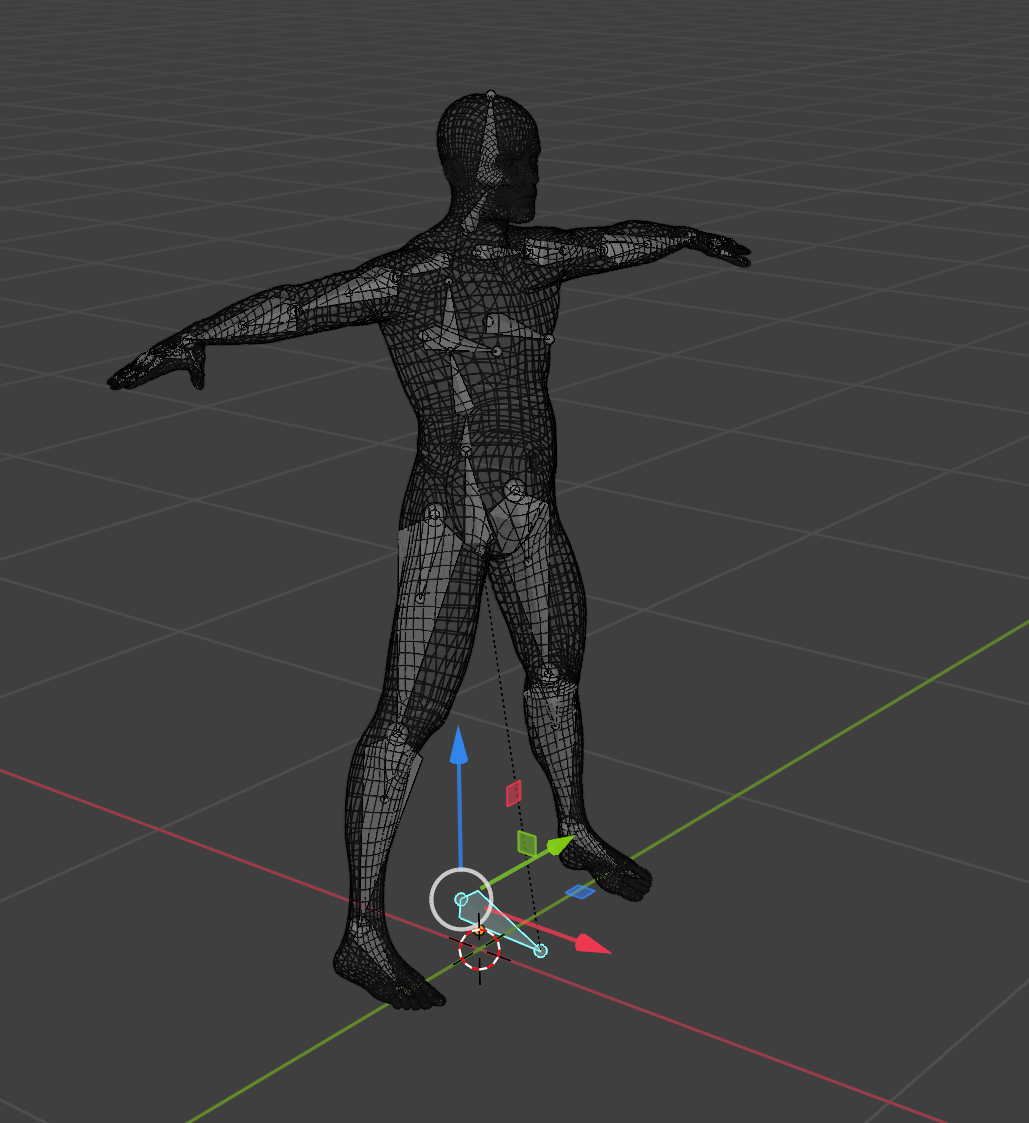
The image above illustrates the aforementioned anchor point (with three axes pointing out of it).
However, we believe there might be better candidates for anchor/reference points, for example a center of the mass of pose skeleton keypoints, but as we have mentioned it is not very important numerically for our task – as long as the reference point located anywhere nearby the person, the ground truth distance and moreover depth will be very similar.
In favor of depth (against distance)
So what should our model predict? Distance? Depth? Note, we are not talking about the representation of this value yet, like normalized, log, or inverse. Our current concern is to select the base physical property: distance or depth, and then we can discuss how to obtain it from the raw model output domain.
According to the task formulation at the beginning of this article, ultimately, we are interested in distance, i.e., range to a person. But knowing the focal length of the camera, (sub-) pixel coordinates of the human reference point projection on the image, and the depth (Z coordinate), we can find the person’s 3D coordinates in the camera system, and then compute the distance as Distance=sqrt(X2+Y2+Z(i.e. Depth)2).
Why might we want to predict depth instead of distance? Thinking of features that a model would learn, we expect the model to develop an understanding of the 3D location of a person based on the appearance of the person in the image. Trying to put our expectations of the insights learned by a Deep Learning model into human-understandable words, those might be something like:
- What is the area of a person’s face?
- What is the frequency response of the region where we assume the person to be? In other words, how much detail do we see in the person region?
- How smooth is the contour of the person’s silhouette?
- What are the lengths of the segments between the person’s joints (pose skeleton bone lengths)?
- Or simply, what is the person’s height?
These features stay more or less invariant to a person’s translation parallel to XY. But they vividly change with the change of Z (depth). In other words, the distance itself doesn’t necessarily impact the appearance of a person’s projection on the image much, as long as the person doesn’t change their Z coordinate. To demonstrate it we created a scene in Blender with three people (Shown on the image below). Note that Blender’s coordinate system differs from the one described previously in this article. It doesn’t matter much for conveying our point, though. The person in the middle is the reference one. The person to the right has the same depth as the reference person but a different distance (w.r.t. the camera’s coordinate system). The person to the left has the same distance but lower depth.
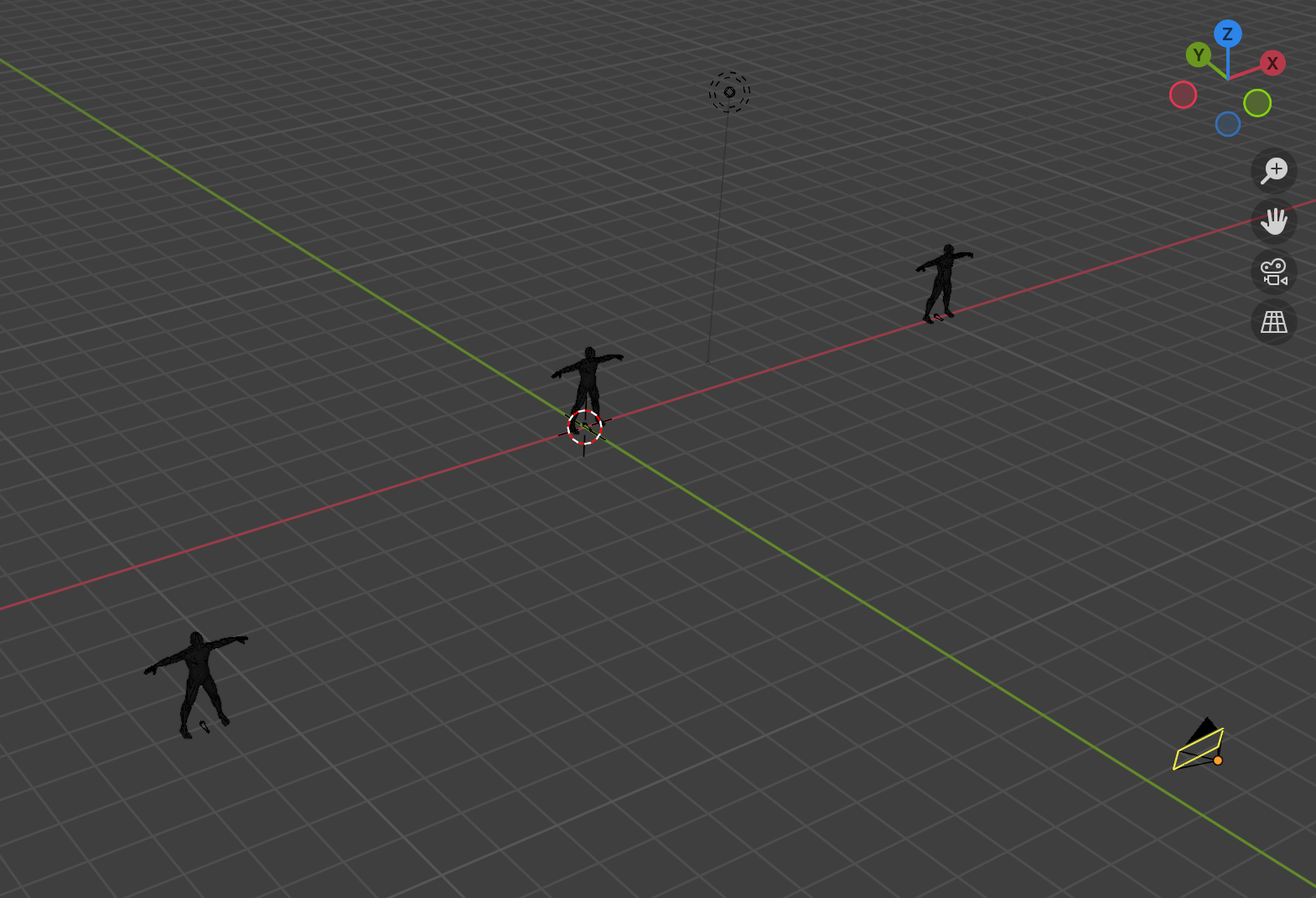
Below are renders of what the camera sees. These renders make it obvious that the Z coordinate (depth) is more important for the person’s appearance in the image: the middle and the right people’s projections remain of the same height, and of the same pose bones lengths, when the left person appears bigger. It is specifically obvious on the render with guide lines overlay, comparing the projection sizes of people in the image.
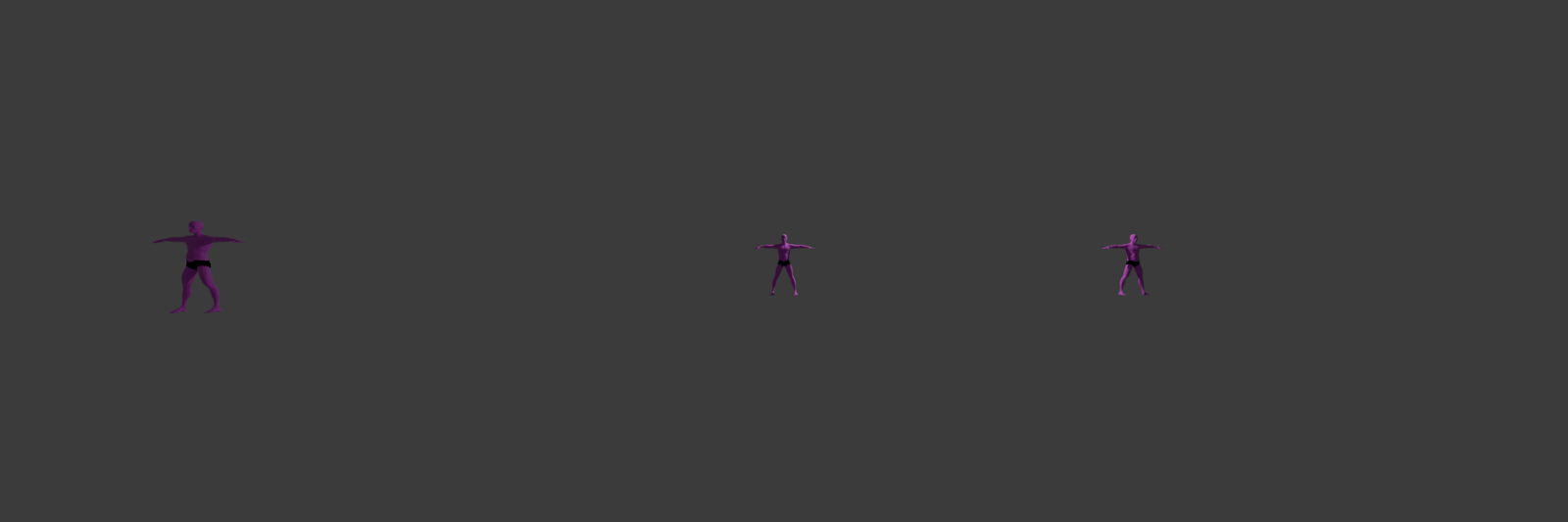
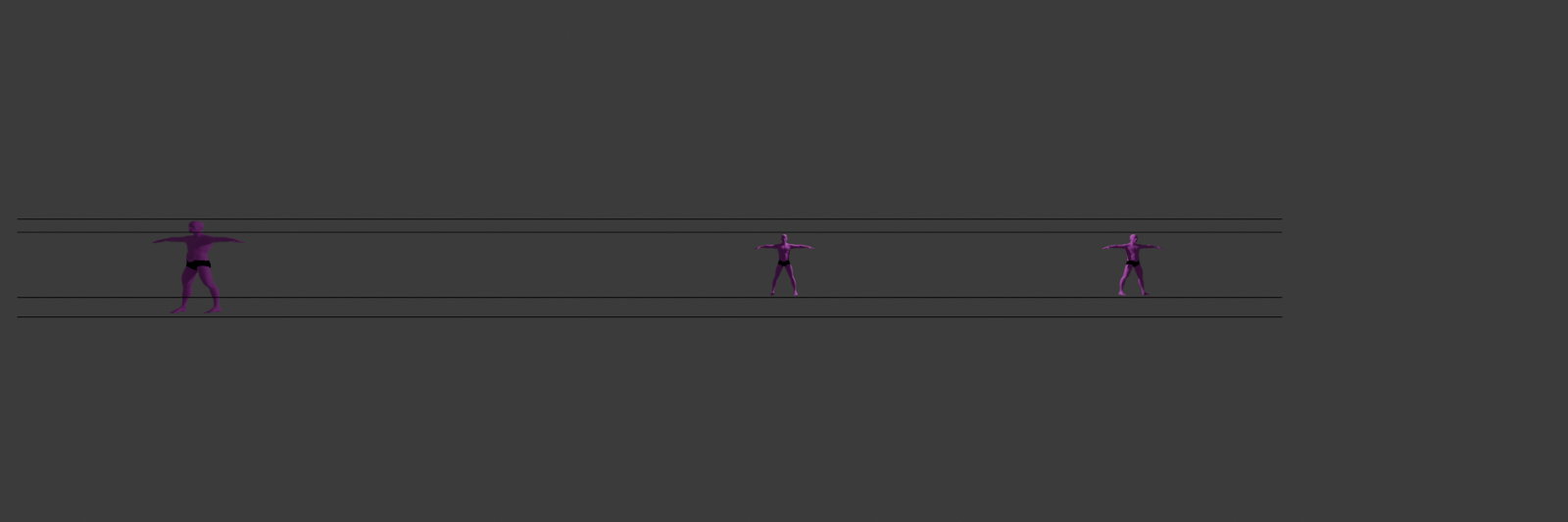
Considering the phenomenon described above, we believe it is more reasonable to hope for a model to learn depth rather than distance directly. Which doesn’t mean we sacrifice the knowledge of distance, because as it was mentioned earlier, after we predicted depth, knowing the location of the person’s anchor point on the image and the focal length, we can compute 3D coordinates of the anchor point, and then compute the distance.
Miscellaneous
Projection size VS Distance
In all papers on depth estimation and 3D detection we have seen so far, the limitations of approaches are described in terms of meters. This is not a particularly informative metric, as the appearance of an object at the same depth from the camera will vary depending on the focal length.
Since we are interested in depth estimation specifically to people, we suggest to express the model’s performance not w.r.t. depth, but w.r.t. the size of the person’s projection. Such a measure of size can be the area of a person in the image in pixels. Hence, reporting the results, we will be saying something like: “the model achieves 5% error in distance estimation for people who occupy ~200 pixels on the image”.
Different depth representations
This topic is separate from the Distance VS Depth discussion we had above. There is a Markdown file that covers some of the representations. What is not covered in that article is logarithmic depth, which, just like the inverse depth, provides more resolution to closer distances while compressing the farther distances.
It might be beneficial to research alternative scaling functions that, on the contrary expand the values associated with high depths, which may help the model to perform better at long ranges.
Absolute VS Relative depth
Relative depth aims to predict the order of objects in terms of their Z coordinate, not the actual Z coordinate, sometimes not even up to scale ambiguity. In this task, we deal with absolute depth, first of all because there are no other objects to compare against (single person in the frame), and second, we need the scale of the prediction to be the same regardless of the content of the scene.
To deal with too close / too far depths, we can crop the ranges at values at which we expect to use the model, like:
range = clamp(range, min_range, max_range)
Conclusion
We discussed the difference between depth and distance, and their representations. Now we have a solid foundation to move to a more practical part of this discussion.